Commenters Sylvain B., xpil, and Christian Luca all gave correct answers to the challenge from my previous post. If the probability that someone likes X is  , then the probability they don’t like X is
, then the probability they don’t like X is 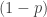 . Therefore the probability that someone doesn’t like anchovies and doesn’t like books is
. Therefore the probability that someone doesn’t like anchovies and doesn’t like books is 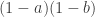 . (If liking anchovies and books are independent, then not liking those things is also independent.) Likewise, the probability that someone doesn’t like all three is
. (If liking anchovies and books are independent, then not liking those things is also independent.) Likewise, the probability that someone doesn’t like all three is  .
.
The reason I asked the question, however, is to see the pattern that emerges if we multiply out these expressions, which commenter Buddha Buck explained.
The first line is the result of multiplying out ; the second is ; and the last is of course  . After expanding everything as much as possible, we get one term for the product of every possible combination of the probabilities, with a positive sign for an even number of probabilities, and negative for an odd number.
. After expanding everything as much as possible, we get one term for the product of every possible combination of the probabilities, with a positive sign for an even number of probabilities, and negative for an odd number.
Do you see why this happens? Each term in the result arises from choosing one of the two possible terms from each parenthesized expression. Taking as a specific example, we get 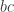 if we choose
if we choose  from
from  , and
, and 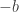 from
from 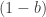 , and
, and 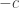 from
from 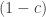 , yielding
, yielding  .
.
And now for a set of follow-up questions. Suppose that  is the set of all people in our population,
is the set of all people in our population,  is the set of people who like anchovies, and
is the set of people who like anchovies, and  is the set of people who like books. Suppose we also know how many people like both anchovies and books, that is, we know
is the set of people who like books. Suppose we also know how many people like both anchovies and books, that is, we know 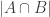 . (The notation
. (The notation 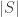 denotes the size of a set
denotes the size of a set  , and
, and 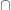 denotes the intersection of two sets, that is, the set of elements the two sets have in common.)
denotes the intersection of two sets, that is, the set of elements the two sets have in common.)
-
How many people like neither anchovies nor books?
-
Now suppose  is the set of people who like carpets. Suppose we also know the sizes of the sets
is the set of people who like carpets. Suppose we also know the sizes of the sets 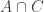 ,
, 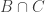 , and
, and  . How many people like none of the things?
. How many people like none of the things?
-
And so on?
About Brent
Associate Professor of Computer Science at Hendrix College. Functional programmer, mathematician, teacher, pianist, follower of Jesus.



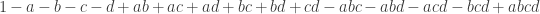

The number of people who like neither anchovies nor books would be: P – |A $\cap B|.
The number of people who like neither anchovies, books, nor carpets would be P – (|A $\cap C| + |B $\cap C| + |A $\cap B $\cap C|).
The number of people who do not like any of the enumerated things considered, which we can call n could be denoted by: P – (|A_1 $\cap A_2| + |A_2 $\cap A_3| + |A_3 $\cap A_4| + …|A_n-1 $\cap A_n| + |A_1 $\cap A_2 $\cap A_3 $\cap A_4…$\cap A_n). |
Not quite. For example, |P| – |A \cap B| is the number of people who don’t like both, which is not the same as people who like neither. In particular it includes people who like one but not the other.
Do you guys mean ‘\cup’, not ‘\cap’, in your LaTeX?
`\cup’ corresponds to union and `\cap’ is intersection. I meant `\cap’ because I was responding to what Christian wrote. And I assume Christian did not typo `\cap’ for `\cup’ thirteen times by accident. =)
If we wish to know how many people like neither anchovies nor books, this would be the size of the intersection of the complements of A and B; that is, . Applying De Morgan’s law, this is equal to $\latex |(A \cup B)’|$. Assuming we know |P|, |A|, and |B|, (which is unfortunately not clear to me in the given statement) then this would be
. Applying De Morgan’s law, this is equal to $\latex |(A \cup B)’|$. Assuming we know |P|, |A|, and |B|, (which is unfortunately not clear to me in the given statement) then this would be
We add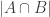 because if we simply subtract |A| and |B| from |P|, we end up subtracting the intersection twice, and so need to counteract this to obtain an accurate value.
because if we simply subtract |A| and |B| from |P|, we end up subtracting the intersection twice, and so need to counteract this to obtain an accurate value.
Similarly, if we wish to know how many people like neither anchovies nor books nor carpet, this is the size of the intersection of the complements of A, B, and C; that is, . Again applying De Morgan’s Law, this is equal to
. Again applying De Morgan’s Law, this is equal to  , which, assuming we also know |C|, is equal to
, which, assuming we also know |C|, is equal to
Here we add the sizes of the pairwise intersections of sets for the same reason as in the previous paragraph, but in doing so overshoot on ; the size of this subset has been subtracted three times from |P| and then added back three times with
; the size of this subset has been subtracted three times from |P| and then added back three times with 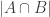 ,
, 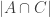 , and
, and  . Thus we need to subtract
. Thus we need to subtract 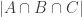 one last time to obtain an accurate value.
one last time to obtain an accurate value.
In general, let P be the set of all people in our population and let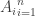 be a finite collection of subsets of P containing people who like thing i. Then, following the pattern and assuming we know the sizes of P and of every finite intersection of sets
be a finite collection of subsets of P containing people who like thing i. Then, following the pattern and assuming we know the sizes of P and of every finite intersection of sets  , the number of people who like none of the things should be equal to
, the number of people who like none of the things should be equal to
This is in direct correlation with the result outlined in the blog post (where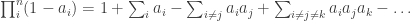 ), suggesting a relationship between multiplication of probabilities and intersection of sets.
), suggesting a relationship between multiplication of probabilities and intersection of sets.
Pingback: Have a piece of PIE | The Math Less Traveled
Pingback: A combinatorial proof: reboot! | The Math Less Traveled