[Disclosure of Material Connection: Princeton Press kindly provided me with a free review copy of this book. I was not required to write a positive review. The opinions expressed are my own.]
Tales of Impossibility: The 2000-Year Quest to Solve the Mathematical Problems of Antiquity
David S. Richeson
Princeton University Press, 2019
Let me get right to the point: this was hands-down my favorite math book that I read this year. If you don’t already have a copy, you should stop reading this post right now and go buy one! Go on, you’ll thank me. Need more convincing? Read on.
The book is focused around the four “problems of antiquity”: squaring the circle (i.e. constructing a square with the same area as a given circle), angle trisection, doubling the cube (constructing the side length of a cube double the volume of a given cube), and constructing regular  -gons. The “problem” of each is to carry out the required construction using only a compass and straightedge (a set of tools that is probably familiar to most readers from some point in their mathematical education). As Richeson so ably relates, these problems inspired all sorts of advances in mathematics over thousands of years—even though (because?) all were eventually proved impossible in general: Wantzel (angle trisection, doubling the cube, regular -gons) and Lindemann (squaring the circle) gave the final, definitive proofs, but both built on top of a great deal of mathematics that came before them. Each new player in the story added layer upon layer of understanding over thousands of years.
-gons. The “problem” of each is to carry out the required construction using only a compass and straightedge (a set of tools that is probably familiar to most readers from some point in their mathematical education). As Richeson so ably relates, these problems inspired all sorts of advances in mathematics over thousands of years—even though (because?) all were eventually proved impossible in general: Wantzel (angle trisection, doubling the cube, regular -gons) and Lindemann (squaring the circle) gave the final, definitive proofs, but both built on top of a great deal of mathematics that came before them. Each new player in the story added layer upon layer of understanding over thousands of years.
First and foremost, I am amazed at the incredible amount of historical and mathematical background research that Richeson obviously did for this book, and the way he intertwines mathematics and history into a compelling story. Stereotypically, a book of mathematical history runs a double risk of being dry: too much unmotivated historical or mathematical detail can put anyone to sleep. Richeson deftly avoids this trap, and his book exudes human warmth. But it doesn’t skimp on details either; I learned a great deal of both history and mathematics. In many cases (such as with many of the purely geometric arguments) proofs are included in full detail. In other cases (such as in the discussion of irreducible polynomials), some mathematical details are omitted. Richeson has a good nose for sniffing out the most elegant way to present a proof, and also for knowing when to omit things that would bog down the story too much.
Alternating with the “regular” chapters, Richeson includes a number of “tangents”, each one a short, fascinating glimpse into some topic which is related to the previous chapter but isn’t strictly necessary for driving the story forward (e.g. toothpick constructions, Crockett Johnson, origami, the Indiana pi bill, computing digits of pi, the tau vs pi debate, etc.). Even though none of them are strictly necessary, taken as a whole these “tangent” chapters do a lot to round out the story and give a fuller sense of the many explorations inspired by the problems of antiquity.
In addition to the many mathematical and historical details I learned from the book, I also took away a more fundamental insight. I had always thought of “compass and straightedge” constructions as being rather arbitrary: these are the tools the Greeks happened to choose, and so now we are stuck in a rut of thinking about geometrical constructions using these tools—or so I thought. However, it turns out that they are not quite so arbitrary after all: there are many different sets of tools that lead to exactly the same set of constructible things (there is even some interesting history here, as mathematicians figured out what it should even mean to say that you can “construct the same things” with different tools, leading to definitions of constructible points and constructible numbers). For example, toothpicks, a straightedge and “rusty” compass, a straightedge and a single circle, a compass by itself, or a “thick” straightedge by itself (with two given starting points), all can perform exactly the same set of constructions as a traditional straightedge and compass. And as we learned in later centuries, the constructible numbers have a nice algebraic characterization as well: a point  is constructible with straightedge and compass if and only if
is constructible with straightedge and compass if and only if  and
and  can be described using the four arithmetic operations and square roots. In other words, the set of constructible points seems to be a robust set that can be described in many equivalent ways; it is a more fundamental notion than the arbitrary-sounding description in terms of compass and straightedge would seem to imply. I don’t think I would have been able to understand this without someone like Richeson to do a lot of research and then put all the details together into a coherent story.
can be described using the four arithmetic operations and square roots. In other words, the set of constructible points seems to be a robust set that can be described in many equivalent ways; it is a more fundamental notion than the arbitrary-sounding description in terms of compass and straightedge would seem to imply. I don’t think I would have been able to understand this without someone like Richeson to do a lot of research and then put all the details together into a coherent story.
[It reminds me of a similar phenomenon with computation: for example, the description of a Turing machine seems rather arbitrary, and in some ways it is, but it turns out that many different models of computation (Turing machines, multi-tape Turing machines, lambda calculus, Post canonical systems, RAM machines…) all yield the same set of computable functions, and so the arbitrary-seeming choice is actually describing something more fundamental.]
In the same way, I thought the problems of antiquity themselves were somewhat arbitrary; but they were famous because they are hard, and it turns out they were hard precisely because they were really getting at the heart of some fundamentally deep ideas. So the fact that they inspired so much rich mathematics is no mere accident of history. One gets the sense that if we ever encounter intelligent life elsewhere in the universe, we may find that they struggled with the same mathematical problems—in very different forms, to be sure, but recognizably the same on a fundamental level.
Anyway, I’ve written more than enough at this point, and I think you get the idea: I thoroughly enjoyed this book, learned a lot from it, and highly recommend it!


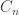
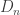





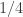
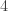
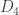
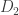

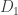




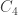
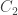


 and
and  :
:
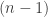 -drawing goes to the right of the first copy; for odd
-drawing goes to the right of the first copy; for odd 

 ) is showing every possible subset a set of
) is showing every possible subset a set of 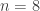 but it gets very hard to see what’s going on after
but it gets very hard to see what’s going on after 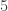 .)
.)



 trough through tough though though.
trough through tough though though.
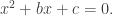
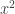 has a coefficient of
has a coefficient of  . (If we have a quadratic equation with some other coefficient
. (If we have a quadratic equation with some other coefficient 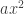 , we can always divide everything by
, we can always divide everything by  first.)
first.)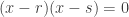
 and
and 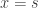 are the two solutions. If we multiply out the above factorization (using, you know, “FOIL”), we get
are the two solutions. If we multiply out the above factorization (using, you know, “FOIL”), we get
 and
and  whose product is
whose product is  and whose sum is
and whose sum is 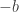 .
. , let’s divide both sides by
, let’s divide both sides by  :
: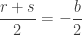
 to denote the distance from
to denote the distance from 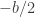 . Since
. Since 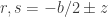

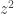 to one side of the equation by itself and take the square root:
to one side of the equation by itself and take the square root:
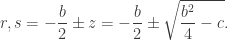
 to derive the usual quadratic formula including an arbitrary value of
to derive the usual quadratic formula including an arbitrary value of  , so there’s no need to memorize a formula at all:
, so there’s no need to memorize a formula at all: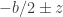 .
. , and solve for
, and solve for  and
and  .
.